What is Data De-duplication?
Data de-duplication is the process of identifying and eliminating duplicate copies of data within a system or across systems. It ensures that only a single, unique instance of data is retained, while redundant duplicates are either removed or referenced using pointers. This technique is widely used in storage optimization, data backup, and cloud infrastructure to reduce the amount of data that needs to be stored or transferred.
In simpler terms, de-duplication ensures you’re not storing the same data more than once, helping reduce storage bloat, improve efficiency, and cut costs.
Why Data De-duplication Matters
In today’s data-intensive environments, enterprises deal with massive volumes of repetitive data, especially in backup and disaster recovery processes. Without de-duplication, this leads to unnecessary storage consumption, longer processing times, and increased infrastructure costs.
According to IDC, data de-duplication can reduce storage requirements by up to 70,% depending on the dataset and application. In enterprise environments where every gigabyte matters, especially with unstructured data growth, this translates into significant savings and performance improvements.
Types of Data De-duplication
- File-Level (Single-Instance Storage): Removes duplicate files by comparing their checksums or hashes. Only one copy of the file is kept; duplicates are replaced with links.
- Block-Level: Breaks files into chunks (blocks) and removes identical blocks across files. More granular and efficient than file-level de-duplication.
- Inline vs. Post-Process:
- Inline: De-duplication happens in real-time as data is written.
- Post-Process: De-duplication occurs after the data is written to storage.
Challenges in Data De-duplication

1. Scalability in Big Data Environments
As organizations accumulate vast amounts of data, traditional de-duplication methods struggle to keep pace. The sheer volume and velocity of big data necessitate scalable solutions that can efficiently identify and eliminate duplicates without compromising performance.
2. Complexity of Unstructured and Semi-Structured Data
The proliferation of unstructured data (like emails, images, and videos) and semi-structured data (such as JSON and XML files) presents significant challenges. These data types often lack consistent formatting, making it difficult for de-duplication algorithms to detect redundancies accurately.
3. Integration with AI and Machine Learning Systems
Incorporating de-duplication processes into AI and machine learning pipelines is essential to prevent model bias and ensure data quality. However, integrating these processes can be complex, requiring sophisticated algorithms that can handle diverse data types and sources.
4. Real-Time De-duplication Requirements
With the rise of real-time data processing and analytics, there’s an increasing demand for de-duplication solutions that operate in real-time. Achieving this requires high-performance systems capable of processing and de-duplicating data on the fly, which can be technically challenging and resource-intensive.
5. Data Privacy and Compliance Concerns
De-duplication processes must comply with data privacy regulations like GDPR and HIPAA. Ensuring that de-duplication doesn’t inadvertently expose sensitive information or violate compliance standards is a significant concern for organizations.
6. Handling Data from Diverse Sources
Organizations often collect data from various sources, including different departments, partners, and third-party providers. The lack of standardization across these sources can lead to inconsistencies, making de-duplication more challenging.
7. Resource Constraints and Performance Overhead
De-duplication processes can be resource-intensive, consuming significant computational power and storage, especially when dealing with large datasets. Balancing the benefits of de-duplication against the performance overhead is a constant challenge.
Addressing these challenges requires a combination of advanced technologies, including AI-driven algorithms, scalable infrastructure, and robust data governance frameworks. As the data landscape continues to evolve, organizations must adapt their de-duplication strategies to maintain data quality, ensure compliance, and optimize storage efficiency.
Rethinking De-duplication: What the Future Looks Like
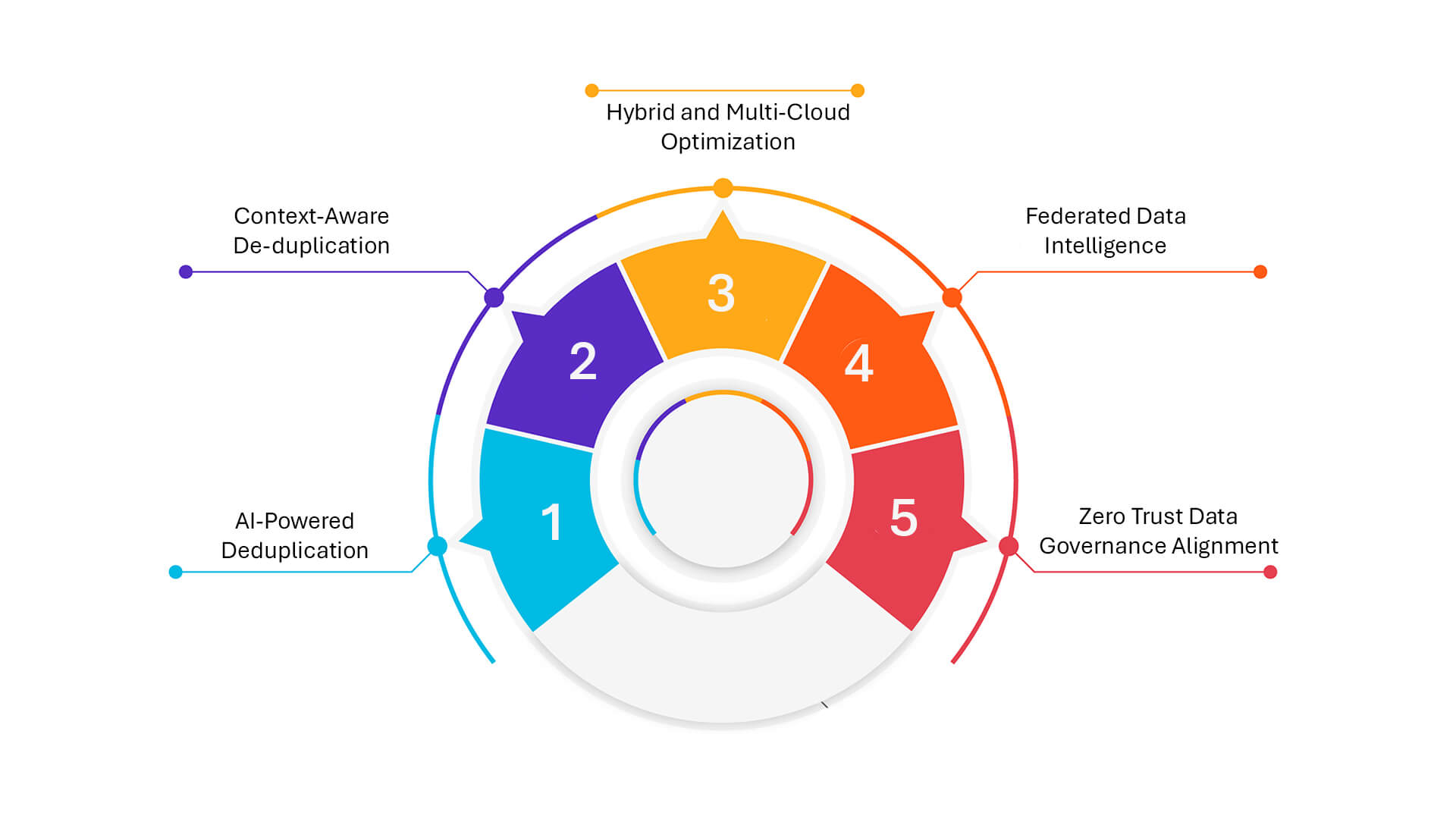
As data volumes grow exponentially and AI models become more reliant on large, clean, and contextually rich datasets, de-duplication is undergoing a transformation—from a backend storage tactic to a front-line strategy for AI and compliance readiness.
- AI-Powered Deduplication: Emerging tools now leverage machine learning to go beyond simple pattern matching. These systems can recognize near-duplicate files even when content has slight variations—think versions of a document saved with different metadata, or images edited with minor changes. This level of intelligence enables smarter de-duplication, especially in unstructured data lakes.
- Context-Aware De-duplication: It’s no longer just about byte-level similarity. Enterprises are increasingly adopting solutions that understand context—recognizing that a duplicate in a healthcare system might carry different privacy implications than one in financial records. By aligning de-duplication efforts with business logic and sensitivity classification, organizations can ensure operational efficiency without compromising compliance.
- Hybrid and Multi-Cloud Optimization: As hybrid cloud becomes the default architecture, deduplication must span across on-prem, public, and private cloud environments. Advanced deduplication engines are now being embedded into cloud storage fabric, enabling consistent optimization across platforms, reducing egress costs, and improving cloud sustainability metrics.
- Federated Data Intelligence: Modern data ecosystems are embracing federated de-duplication—where data is deduplicated not just within silos, but across business units, regions, and cloud zones. This helps eliminate redundancy at the enterprise scale, fueling cleaner AI pipelines and regulatory reporting without centralizing sensitive data unnecessarily.
- Zero Trust Data Governance Alignment: In the age of Zero Trust, de-duplication is being tied to broader governance frameworks. Integrations with access controls, audit trails, and policy enforcement ensure that deduplication doesn’t just clean data—it does so transparently, ethically, and in alignment with security protocols.
Data de-duplication is no longer just a storage optimization technique—it’s a strategic imperative in today’s data-driven enterprises. As organizations navigate the challenges of exponential data growth, unstructured data sprawl, and AI readiness, the ability to intelligently identify and eliminate redundancies becomes critical.
Whether it’s cutting storage costs, accelerating backup and recovery, or ensuring clean, trusted datasets for analytics and AI, de-duplication plays a foundational role in modern data management strategies. With the rise of hybrid cloud infrastructures, regulatory scrutiny, and real-time data processing, the future of de-duplication lies in AI-powered, context-aware, and policy-driven solutions that scale across diverse environments.
For enterprises looking to future-proof their data infrastructure, rethinking de-duplication isn’t optional—it’s essential.
Getting Started with Data Dynamics:
- Learn about Unstructured Data Management
- Schedule a demo with our team
- Read the latest blog: AI, Ethics, and Compliance: The Next Frontier in Global AI Leadership





