What is Data Wrangling?
Data Wrangling is the process of cleaning, transforming, and organizing raw data into a structured format suitable for analysis. This involves identifying and correcting errors, filling in missing values, standardizing data formats, and reshaping data sets to make them consistent and usable. Data wrangling is a crucial step in the data preparation workflow, enabling more accurate and meaningful analysis by ensuring that the data is reliable and ready for use in decision-making processes.
In a world where data is vast, messy, and often unstructured, data wrangling is a foundational step in making data analytics-ready and AI-worthy.
Why Does Data Wrangling Matter?
No matter how sophisticated your analytics tools or AI algorithms may be, their outputs are only as good as the inputs. According to IDC, analysts spend up to 80% of their time just preparing data, not analyzing it. That’s time lost—not just in productivity, but in delayed insights and slower decision-making.
Data wrangling ensures that datasets are clean, consistent, and enriched with metadata, enabling faster, more accurate, and more scalable outcomes. It also helps avoid costly pitfalls like skewed models, compliance issues, or wrong business decisions driven by faulty data.
What Are the Steps Involved in Data Wrangling?
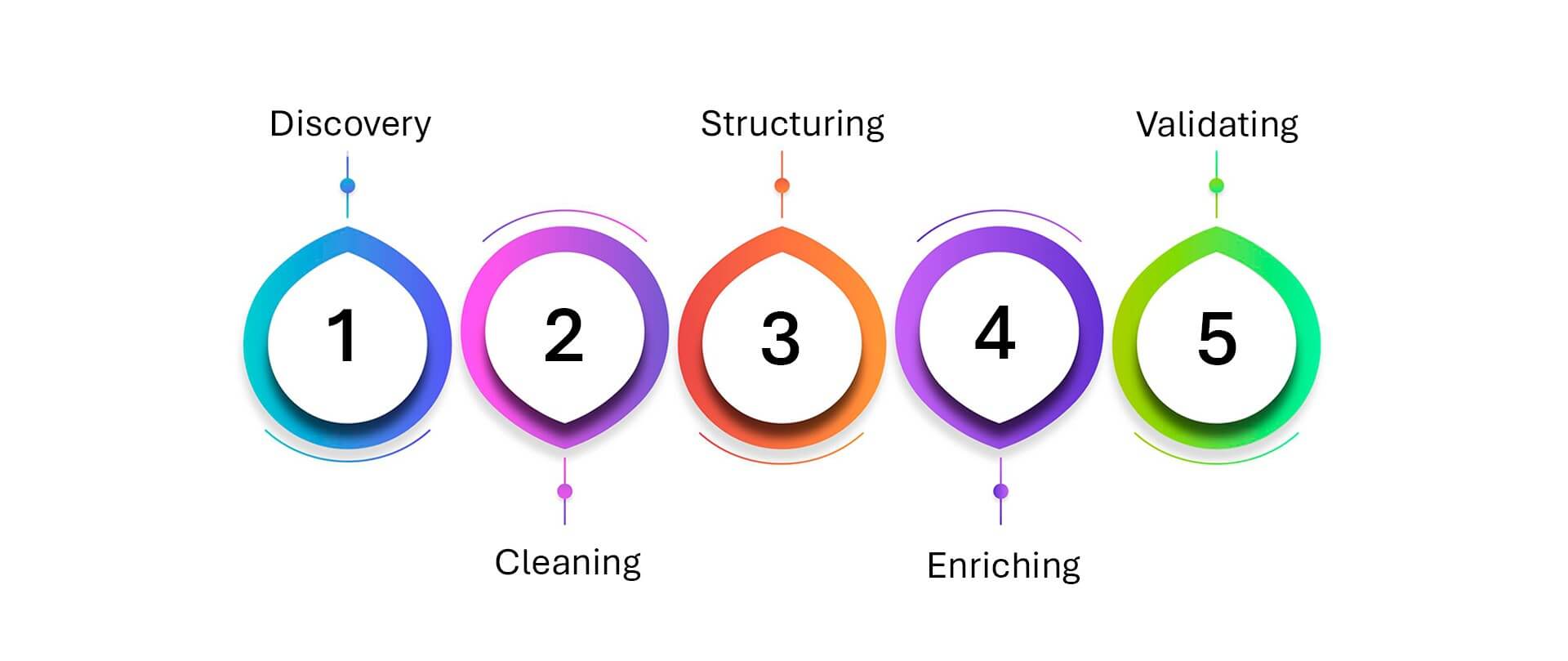
Effective data wrangling includes several key steps, often repeated in iterative loops:
- Discovery: Understanding the structure, types, and anomalies present in raw data, especially important with unstructured or semi-structured formats like PDFs, images, or emails.
- Cleaning: Removing duplicates, fixing typos, resolving inconsistencies, and eliminating irrelevant entries.
- Structuring: Reformatting data into tables, columns, or defined schemas so it’s compatible with target systems.
- Enriching: Adding missing context using metadata, business rules, or third-party sources to improve completeness and usability.
- Validating: Verifying that the transformed data aligns with quality expectations and is ready for analysis or AI modeling.
Modern data wrangling leverages AI and automation to accelerate these tasks, especially in large-scale enterprise environments.
The Challenges of Data Wrangling at Scale
While wrangling a small spreadsheet might be simple, enterprises face far greater complexity:
- Unstructured and Semi-Structured Chaos: From audio files and IoT data to email archives, most enterprise data isn’t neatly organized. Identifying relevant attributes and patterns can be daunting without automation.
- Hidden ROT and Sensitive Content: Data wrangling requires identifying and eliminating ROT (Redundant, Obsolete, Trivial) data, while protecting sensitive information like PII or PHI that could trigger regulatory risks.
- Volume and Variety: With petabytes of data scattered across shared drives, NAS devices, and cloud buckets, the variety of formats and inconsistent tagging make scalable wrangling a challenge.
- Compliance Requirements: GDPR, HIPAA, and DPDP Act regulations demand visibility into how data is prepared and used. Poorly wrangled data can lead to blind spots and compliance breaches.
Data Wrangling in the AI and Analytics Pipeline
In the context of AI and data analytics, data wrangling acts as the bridge between raw, unusable data and trustworthy insights. It’s the layer that adds structure to chaos and context to content.
Wrangled data ensures that AI models are trained on consistent, bias-free, and high-fidelity information, boosting model accuracy, reducing hallucinations, and enabling ethical usage.
In enterprise analytics, it powers confident decision-making by eliminating noise and enhancing data observability.
At Data Dynamics, we view data wrangling as a core pillar of data intelligence. Our AI-powered solutions automate the discovery, cleansing, enrichment, and restructuring of unstructured data across hybrid and cloud environments.
With metadata analytics, automated classification, and policy-driven workflows, our platform ensures that only clean, relevant, and compliant data fuels your analytics or AI pipelines. Whether it’s preparing data for a cloud migration or curating datasets for generative AI models, intelligent wrangling is at the heart of it.
Data wrangling isn’t just a technical process—it’s a strategic advantage. In a world where raw data is abundant but usable data is rare, the ability to efficiently wrangle at scale is what sets insight-driven organizations apart.
Getting Started with Data Dynamics:
- Learn about Unstructured Data Management
- Schedule a demo with our team
- Read the latest blog: Data-Driven by Design: The CIO-CDO Playbook for AI Transformation in the Middle East





