The pharmaceutical industry is experiencing a rapid surge in data generation, driven by advances in research, clinical trials, and patient data collection. While this data explosion offers immense potential for innovation and improving healthcare outcomes, it also presents significant challenges in terms of managing and storing vast amounts of information. As the volume, velocity, and variety of data continue to grow, so do the costs associated with its management and storage. In this context, storage divestitures have emerged as a strategic approach to address the increasing costs of managing data in the pharmaceutical industry. By strategically offloading storage assets and leveraging alternative solutions, such as the cloud, organizations can optimize costs, improve operational efficiency, and unlock new opportunities for innovation. This article explores how storage divestitures can be a cost-effective solution to mitigate these challenges while ensuring data availability, security, and compliance. But first, we need to understand what is a storage divestiture?
Exploring the Concept of Storage Divestiture
Storage divestiture refers to transferring or offloading storage assets or resources from on-premises infrastructure to a cloud provider or from one cloud service provider to another. It involves the strategic decision to reallocate or redistribute storage-related responsibilities and resources to optimize costs, performance, security, or other factors. Storage divestiture may occur due to various reasons, such as:
- Cost optimization: Organizations may seek alternative storage providers or solutions that offer better pricing models, more competitive rates, more capacity utilization or improved cost efficiency. For instance, the average cost of storing a single TB of file data can go over $3,351 a year irrespective of usage. Instead, an enterprise can leverage pay-per-use cloud storage to reduce costs.
- Performance or scalability requirements: Changing storage needs, such as increased data volumes or performance demands, might necessitate divestiture. Organizations may move their storage assets to a provider with better performance capabilities or scalable storage options to meet their evolving requirements.
- Vendor lock-in avoidance: Organizations may choose to divest storage assets from a particular provider to avoid being overly dependent on a single vendor. By diversifying their storage solutions across multiple providers or infrastructure options, they can reduce the risk of being locked into a specific vendor’s ecosystem.
- Security and compliance considerations: In some cases, organizations may divest storage assets from a particular provider if they have concerns about security, data privacy, or regulatory compliance. They may opt for a provider with stronger security measures or better compliance certifications.
Storage divestiture involves migrating data from one storage service to another, reconfiguring storage infrastructure, and updating applications or systems to work seamlessly with the new storage provider. The process typically requires careful planning, data migration strategies, and coordination between the organization and respective service providers to ensure a smooth transition without data loss or service disruptions. Here are seven steps to consider before moving ahead with a divestiture.
Seven Steps for Optimizing Data during Divestitures
When embarking on the journey of storage divestiture, the first step is to thoroughly assess and evaluate your current storage infrastructure and requirements. This step helps you understand your existing storage environment and sets the foundation for making informed decisions throughout the divestiture process. While the assessment process itself does not directly minimize your data estate, it provides crucial insights that can inform subsequent steps focused on data optimization. By assessing your existing storage infrastructure and data assets, you can discover ways to reduce your data estate, allowing you to migrate and store only necessary data, thereby controlling data sprawl. Here are some steps to get you started
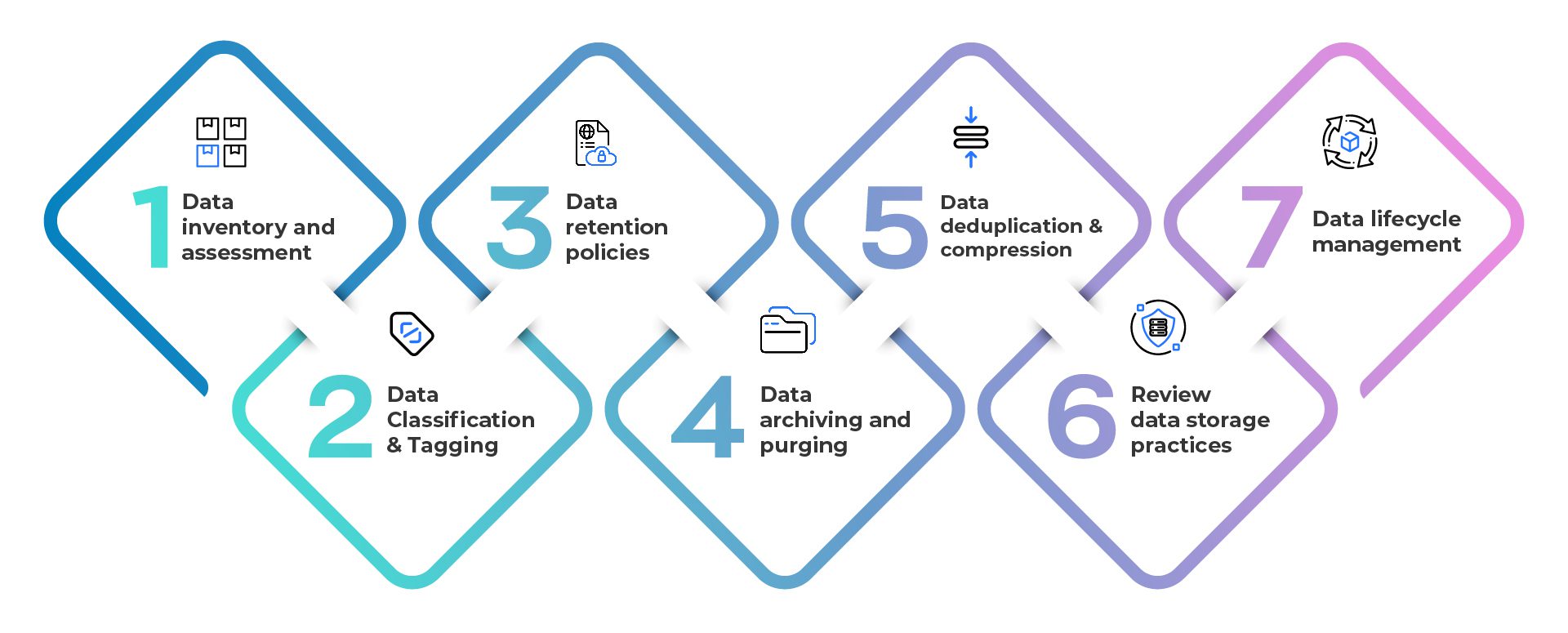
- Data inventory and assessment: During the assessment, you conduct a comprehensive inventory of your data assets and evaluate their relevance and value to your organization. What and where is the data? Do I need all the data? Who has access? Is it secured and compliant? – are just some of the overarching inquiries can be addressed that can be answered during this process.
- Data Classification & Tagging: This step allows you to identify, classify, tag and index data based on usage, age, access, importance, sensitivity, and legal or regulatory requirements. Metadata, content and context analytics can be used to help you gain a better understanding of data sets that can be retained (hot data), archived (cold data) or eliminated (redundant, obsolete, and trivial (ROT) data) as part of the divestiture.
- Data retention policies: As part of the assessment, you establish policies defining how long different data types should be retained. This step helps identify data that has exceeded its retention period (ROT) typically due to age, access, ownership and compliance and can be safely disposed of during the divestiture process, thereby reducing the data estate.
- Data archiving and purging: Implement a data archiving strategy to move inactive or rarely accessed data (Cold) to long-term storage. Archiving helps free up primary storage resources while ensuring data availability when needed. Establish proper procedures and safeguards for data retrieval from archives.
- Data deduplication and compression: Implement data deduplication and compression techniques to reduce storage requirements. Deduplication identifies and eliminates duplicate data, while compression reduces the size of data files. These techniques can significantly reduce storage needs, particularly for backup and archival data.
- Review data storage practices: Evaluate your data storage practices and identify opportunities for optimization. Determine if all data needs to be stored in high-cost primary storage. Consider moving infrequently accessed or archival data to lower-cost storage options, such as cloud-based object storage or tape archives.
- Data lifecycle management: Implement robust data lifecycle management practices that define the stages of data from creation to disposal. Automate data lifecycle processes to ensure consistent and systematic data minimization practices across your organization.
Cloud computing plays a pivotal role in storage divestiture by providing organizations with a flexible and scalable platform for data management. Organizations can offload the responsibility of managing and maintaining physical storage infrastructure, thereby reducing operational costs and complexity. But the silver lining here is the ability to tier your data based on usage.Not only can you achieve cost savings, but you can also enhance efficiency and productivity in your core business functions by harnessing the power of high-speed computing. Let’s explore the concept of cloud tiering and its benefits for businesses.
How can Cloud Tiering help?
Cloud tiering refers to the process of intelligently categorizing and migrating data across different storage tiers based on its frequency of access, importance, and cost considerations. It involves segregating data into multiple tiers, such as hot, warm, and cold storage, and dynamically moving it between these tiers as per predefined policies.
Hot storage, also known as primary storage, houses frequently accessed and critical data that requires low latency and high-performance. Warm storage contains data that is accessed less frequently but is still relevant and requires moderate performance. Cold storage comprises rarely accessed or archived data that demands minimal performance at a significantly lower cost.
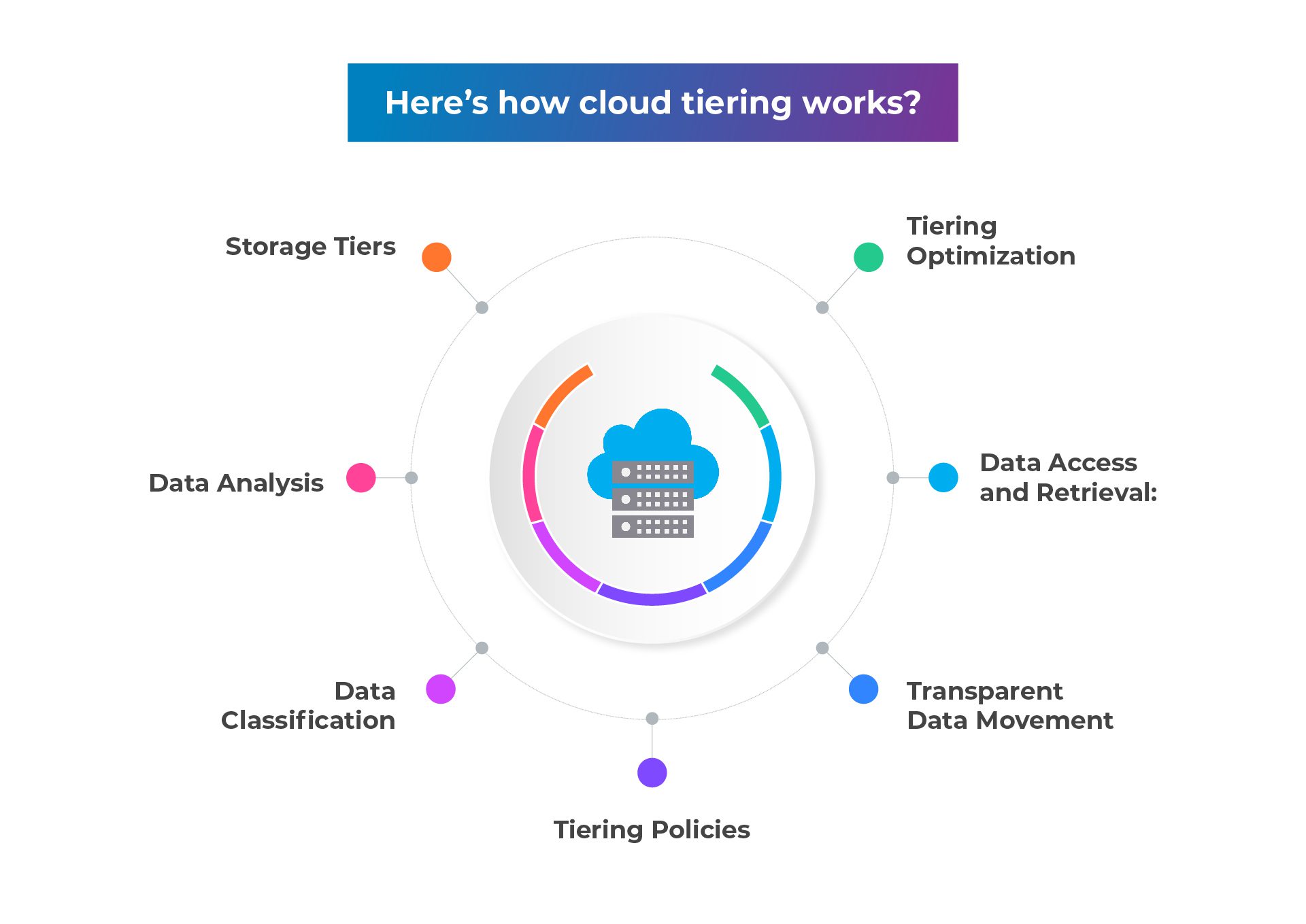
- Storage Tiers: The first step is to set up multiple storage tiers based on their performance, cost, and accessibility characteristics. Typically, there are two or more tiers involved, such as high-performance solid-state drives (SSDs) and lower-cost, high-capacity hard disk drives (HDDs).
- Data Analysis: Cloud tiering systems analyze the data usage patterns within the storage infrastructure. This analysis includes monitoring the frequency of data access, the size of the data, and other relevant factors. This step helps identify data that is frequently accessed and data that is less frequently accessed.
- Data Classification: Based on the data analysis, the cloud tiering system classifies the data into different categories or tiers. Frequently accessed or “hot” data is placed in the higher-performance tiers, such as SSDs, while less frequently accessed or “cold” data is moved to lower-cost, high-capacity tiers like HDDs.
- Tiering Policies: Administrators define tiering policies that determine when and how data should be moved between different storage tiers. These policies may consider factors like data age, access frequency, file size, or specific user-defined rules. For example, a policy might state that data not accessed for a certain period should be moved to a lower tier.
- Transparent Data Movement: Once the tiering policies are defined, the cloud tiering system automatically and transparently moves the data between different storage tiers. The data movement process is usually orchestrated by the cloud storage platform or a dedicated tiering service. It may involve copying, migrating, or archiving the data based on the policies and the available storage resources.
- Data Access and Retrieval: Cloud tiering ensures that data remains accessible to users and applications regardless of its physical storage location. When a user or application requests data that has been moved to a lower tier, the tiering system retrieves the data from the appropriate tier and presents it seamlessly, as if it were stored in the original location. This process is transparent to the end-users.
- Tiering Optimization: Over time, the cloud tiering system continues to monitor data usage patterns and adjusts the data placement accordingly. It dynamically optimizes the storage infrastructure by promoting hot data to higher-performance tiers and demoting cold data to lower-cost tiers. This ongoing optimization helps ensure that frequently accessed data remains readily available while reducing costs associated with storing less frequently accessed data on expensive storage media.
Implementing Cloud Tiering in the Pharmaceutical Sector: Recommended Data Management Best Practices
- Identify the data that can be tiered: The first step is to identify which data can be moved to lower-cost storage tiers. Metadata analysis lays the foundation for enterprises to understand the data itself. Characteristics such as file ownership, processes/departments that are the largest consumer of data, when files were created, when files were last accessed, and what type and size files are just some of the data points captured and provided for reporting and decision making. Check out Data Dynamics’ Analytics suite for more information.
- Define a data retention policy: It’s important to define a retention policy for each data type. This policy should outline how long the data needs to be retained and the frequency of access. This will help determine the storage tier each data type should be moved to.
- Choose the right cloud storage provider: There are many cloud storage providers available, and it’s important to choose one that meets the needs of the pharmaceutical sector. Factors to consider include security, compliance, and performance. Microsoft is one such provider that provides enterprises with best-in-class cloud tiering capabilities.
- Consider hybrid cloud storage: A hybrid cloud storage solution can provide the best of both worlds. This approach allows organizations to keep frequently accessed data on-premises while moving infrequently accessed data to the cloud.
- Implement automation: Cloud tiering can be complex, especially for large amounts of data. Implementing automation can help ensure that data is moved to the appropriate storage tier promptly and efficiently. Policy-based file data migration from heterogeneous storage into the private and public cloud and on-premises storage ensures minimal risk with automatic access control and file security management. Check out Data Dynamics’ Mobility suite for more information.
- Monitor and manage data: It’s important to monitor and manage data regularly to ensure it is stored in the appropriate storage tier. This includes monitoring access patterns and adjusting retention policies as needed. The optimum solution is to use a unified data management software that gives you a single-pane view of enterprise data and drives cloud data management. Check out Data Dynamics’ Data Management Platform for more information.
- Ensure data security: Cloud tiering can introduce new security risks, such as data breaches and data loss. It’s important to identify senstive/PII/PHI data and implement appropriate security measures, such as data quarantine, encryption, access controls and audit controls, to protect data at all times. One can gain insight into the data through content and context analysis during and after migration to secure, remediate the PII/sensitive data and meet compliance requirements. Check out Data Dynamics’ Security suite for more information.
By following best practices and considering these factors, pharma companies can successfully implement cloud tiering to optimize their data storage and management practices, reduce storage costs, and enhance data security and compliance.
Microsoft Azure: Your Partner of Choice
Microsoft provides a range of thrilling cloud tiering choices to help organizations enhance storage and cost effectiveness. The first and foremost is Azure Files, which empowers the classification of file shares into hot and cool storage tiers. By utilizing Azure Files, frequently accessed files can be stored in the hot tier for speedy retrieval, while less accessed files can be automatically shifted to the cool tier to save on expenses. This tiering choice offers a blend of performance and cost optimization, enabling organizations to make the most of their storage resources.
The second tier is Azure Blob Storage. Blob storage tiering permits organizations to categorize their object storage data into various access tiers, including hot, cool, and archive tiers. The hot tier suits frequently accessed data, while the cool tier is ideal for infrequently accessed information. For long-term retention, the archive tier presents a cost-efficient solution. With Azure Blob Storage tiering, organizations can dynamically adjust storage costs based on data access patterns and lifecycle.
Moreover, Microsoft presents Azure Data Lake Storage, which delivers a hierarchical file system with built-in tiering capabilities. Data Lake Storage empowers organizations to categorize their data into hot, cool, and archive tiers, similar to Azure Blob Storage. This tiering option proves particularly exciting for big data and analytics workloads as it provides scalable storage with cost optimization. By automatically classifying data based on usage patterns, organizations can ensure immediate availability of frequently accessed data while minimizing expenses for less accessed or archived data.
In essence, Microsoft’s array of cloud tiering options, such as Azure Files, Azure Blob Storage, and Azure Data Lake Storage, offers a thrilling opportunity for organizations to optimize storage and cost effectiveness. These choices allow for automated classification of data into different storage tiers based on access patterns and lifecycle, whether it’s for file shares, object storage, or big data workloads. With Microsoft’s cloud tiering options, organizations can embrace flexibility and scalability in efficiently managing their cloud storage.
The Data Dynamics Advantage
Data Dynamics Unified Data Management Platform uses analytics to intelligently tier data to Azure by collecting data about how data is being used. This data is then used to create policies that automatically move data to different storage tiers based on its usage patterns, optimizing costs by placing the data in the most cost-efficient tier based on its activity level.
For example, Data Dynamics can collect data about how often data is accessed, how much data is being stored, and the size of the data files. This data can then be used to create policies that move data to different storage tiers based on its usage patterns. For example, data that is accessed frequently can be stored in a high-performance tier, while data that is accessed infrequently can be stored in a lower-cost tier. Additionally, data that has not been used for over 365 days and has no compliance regulation attached to it can be deleted or moved to a long-term storage tier. This helps to free up storage space and reduce costs.
Here are some additional details about how the platform helps with intelligent data tiering to Azure:
- Automated data migration: Automatically migrate data from on-premises storage to Azure in a number of ways, including:
- File-level migration: Data Dynamics can migrate individual files or folders or shares from on-premises storage to Azure.
- Volume-level migration: Data Dynamics can migrate entire volumes from on-premises storage to Azure.
- Policy-based data tiering: Create policies that automatically move data to different storage tiers based on its usage patterns. This helps to optimize costs by ensuring that data is stored in the most cost-effective tier for its level of activity. For example, you could create a policy that moves data that is not accessed for more than 30 days to the Azure Archive tier.
- Data governance: Implement data governance policies that help to ensure that data is stored securely and compliantly. This can help to protect data from unauthorized access and to meet regulatory requirements. For example, you could create a policy that requires all data to be encrypted before it is stored in Azure.
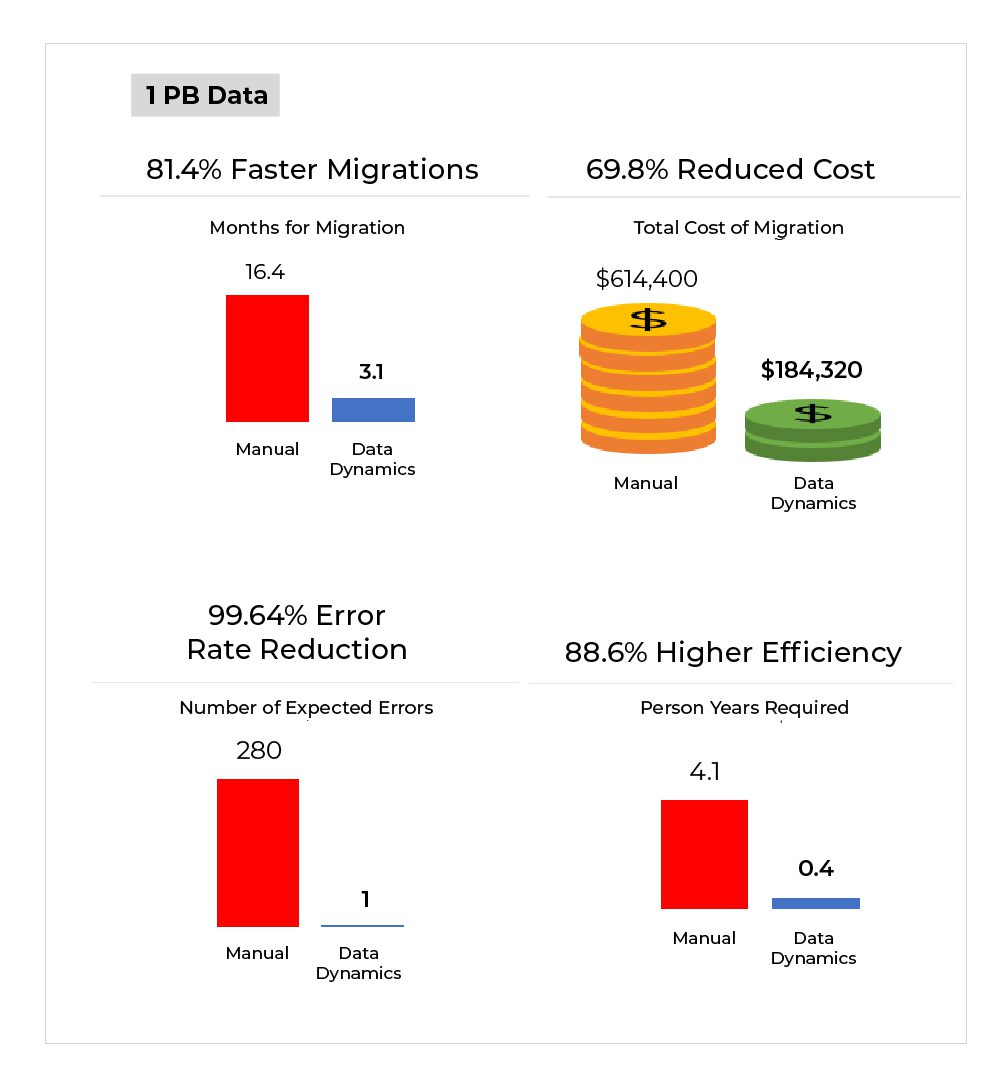
As part of our goal to promote the rapid adoption of cloud technology, Data Dynamics has joined forces with Microsoft to facilitate data migration to Azure for enterprises at no cost. This collaboration enables organizations to transfer their unstructured files and object storage data to Azure without incurring any expenses or requiring additional migration licenses. The migration process is automated, minimizing risks, and includes automatic access control and file security management to ensure data integrity. Furthermore, this partnership enables intelligent data management across On-Premise, Azure, and Hybrid Cloud environments, enhancing overall efficiency and effectiveness. Learn more
Data Dynamics offers a powerful data management platform that can help organizations to move data to Azure, manage it there, and optimize costs. If you are looking for a solution that can help you to achieve these goals, then Data Dynamics is a good option to consider. To learn more about Data Dynamics’ please visit – www.datadynamicsinc.com or contact us at solutions@datdyn.com or call us at (713)-491-4298 or +44-(20)-45520800.





